library(tidyverse)library(targets)library(GGally)library(kableExtra)# load "R/*" scripts and saved R objects from the targets pipelinetar_source()tar_load(c(exp1_data, exp2_data, exp1_data_agg, exp2_data_agg, exp3_data_agg))set.seed(213)# make sure that if the model fails to converge, it doesn't stop the whole processsafe_boot_est <- purrr::safely(boot_est)
Overview
To get an estimate of the uncertainty in the parameter estimates, we can use bootstrapping. This involves resampling the data with replacement and fitting the model to each resampled dataset. We do this:
Resample the IDs of participants in the dataset with replacement.
For each subject, calculate the proportion of correct responses in each condtion and resample the observed counts from a binomial distribution with the probability of success equal to the proportion of correct responses.
Estimate the model parameters from the resampled data.
Repeat steps 1-3 1000 times to get a distribution of parameter estimates.
Experiment 1
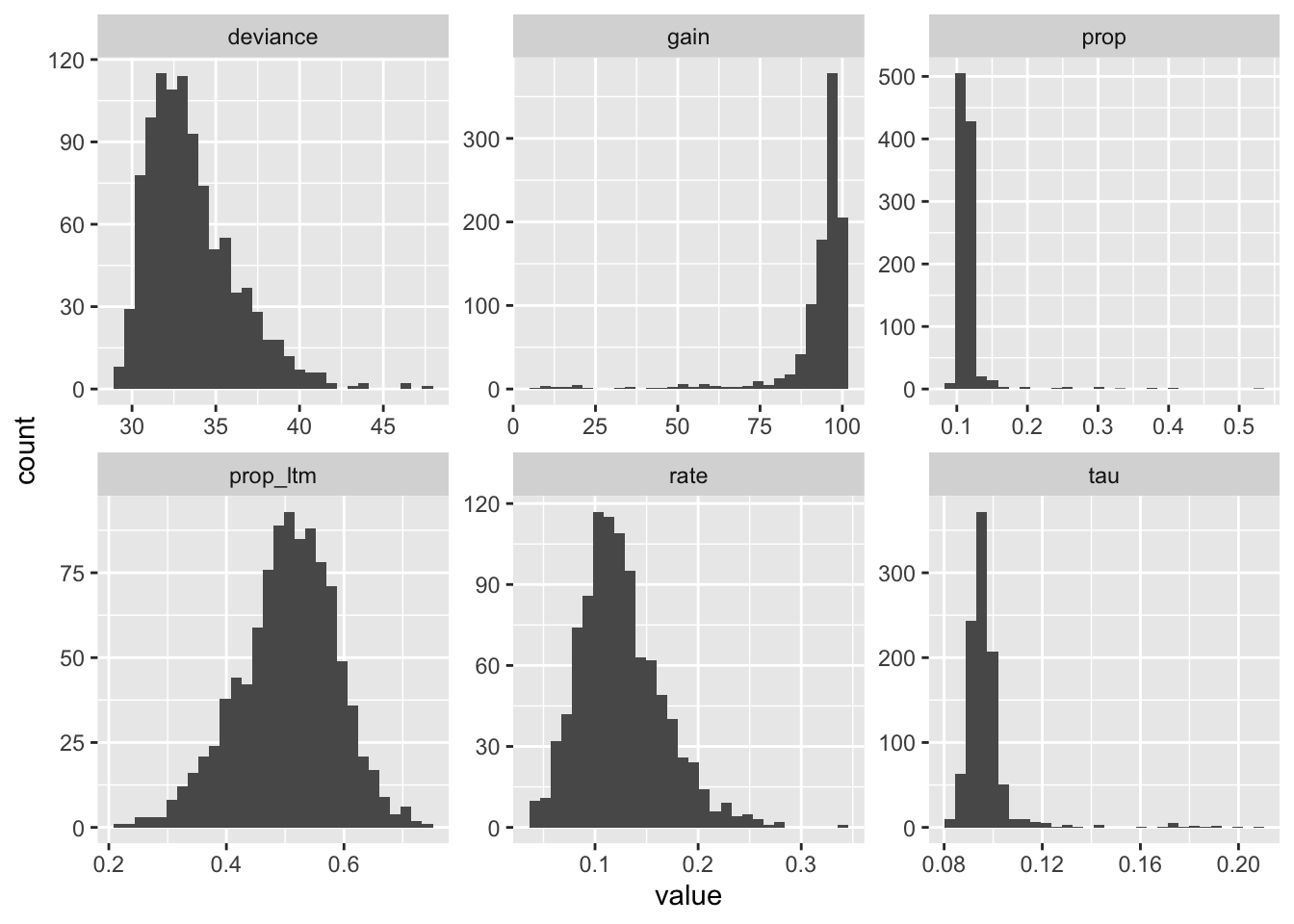
For now I’ve done it just for experiment 1. Here are the results:
---title: "Bootstrapping data and fits for parameter uncertainty estimation"format: html---```{r}#| label: init#| message: falselibrary(tidyverse)library(targets)library(GGally)library(kableExtra)# load "R/*" scripts and saved R objects from the targets pipelinetar_source()tar_load(c(exp1_data, exp2_data, exp1_data_agg, exp2_data_agg, exp3_data_agg))set.seed(213)# make sure that if the model fails to converge, it doesn't stop the whole processsafe_boot_est <- purrr::safely(boot_est)```## OverviewTo get an estimate of the uncertainty in the parameter estimates, we can use bootstrapping. This involves resampling the data with replacement and fitting the model to each resampled dataset. We do this:1. Resample the IDs of participants in the dataset with replacement.2. For each subject, calculate the proportion of correct responses in each condtion and resample the observed counts from a binomial distribution with the probability of success equal to the proportion of correct responses.3. Estimate the model parameters from the resampled data.4. Repeat steps 1-3 1000 times to get a distribution of parameter estimates.## Experiment 1For now I've done it just for experiment 1. Here are the results:```{r}#| label: exp1_bootres_asy <-run_or_load(do.call(rbind, replicate(1000, safe_boot_est(exp1_data)$result)),"output/res_boot1000_asy.rds")plot_bootstrap_results(res_asy)```and here are the 95% highest density intervals for the rate parameters```{r}#| label: exp1_boot_summaryround(HDInterval::hdi(res_asy$rate), 3)```from these bootstrap estimates, we can calculate how long it would take for 50% of the resources to recover from 0 (also see [here](model3_basic_fits.qmd#summary)). ```{r}#| label: exp1_boot_summary2t_est <--log(0.5) / res_asy$rateround(HDInterval::hdi(t_est), 3)```It would take on average $`r mean(t_est)`$ seconds for 50% of the resources to recover from 0, with a 95% HDI of $`r HDInterval::hdi(t_est)`$.