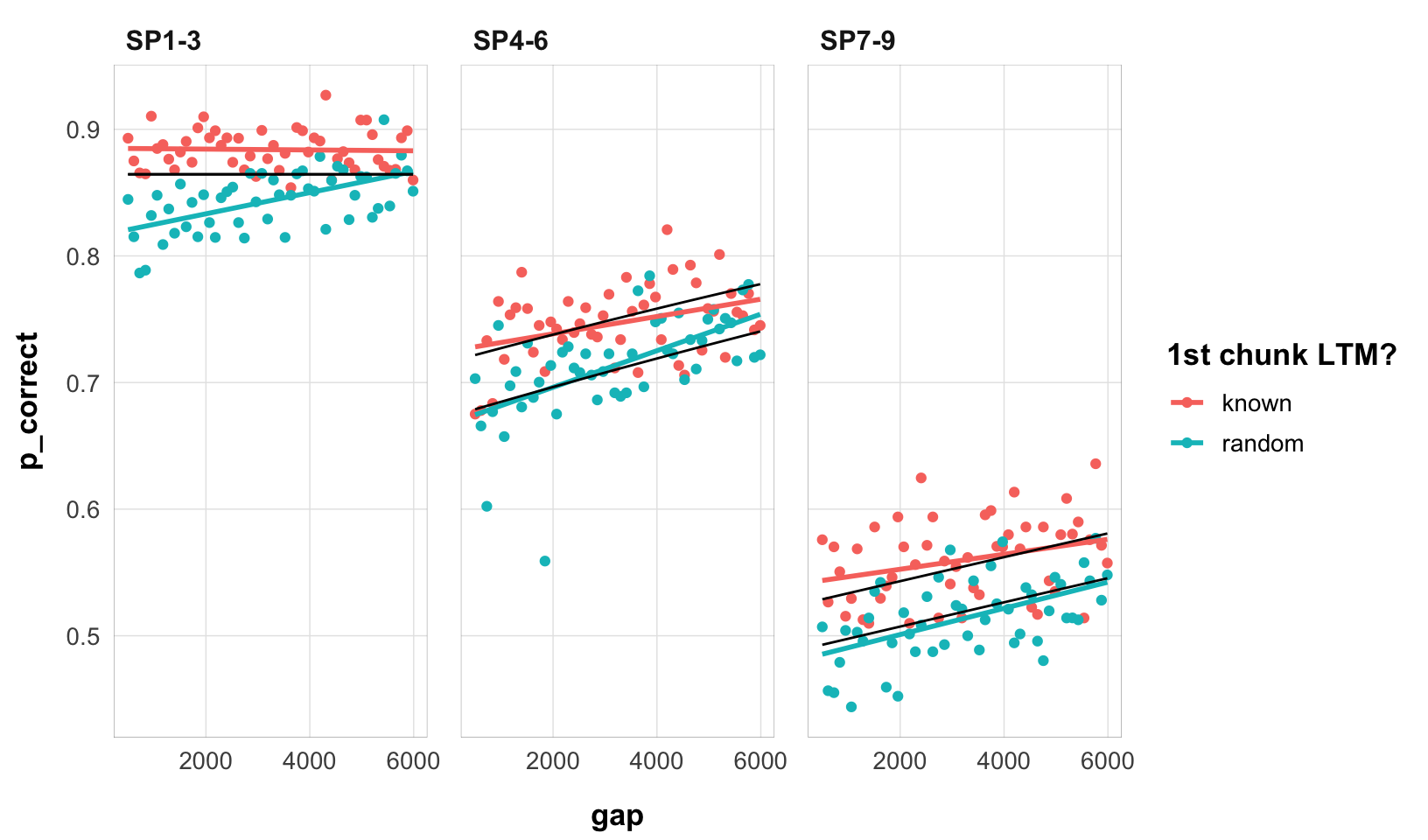
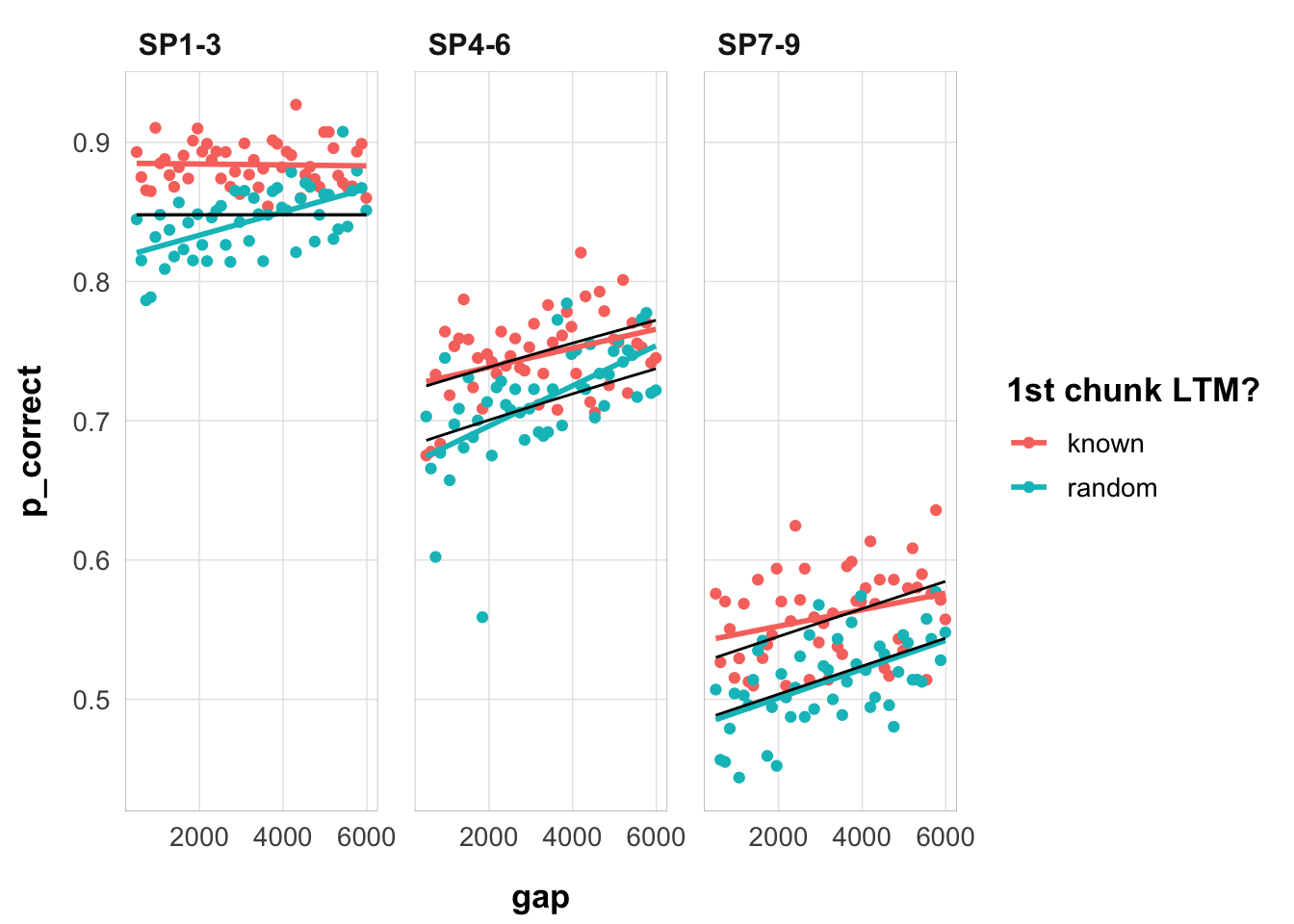
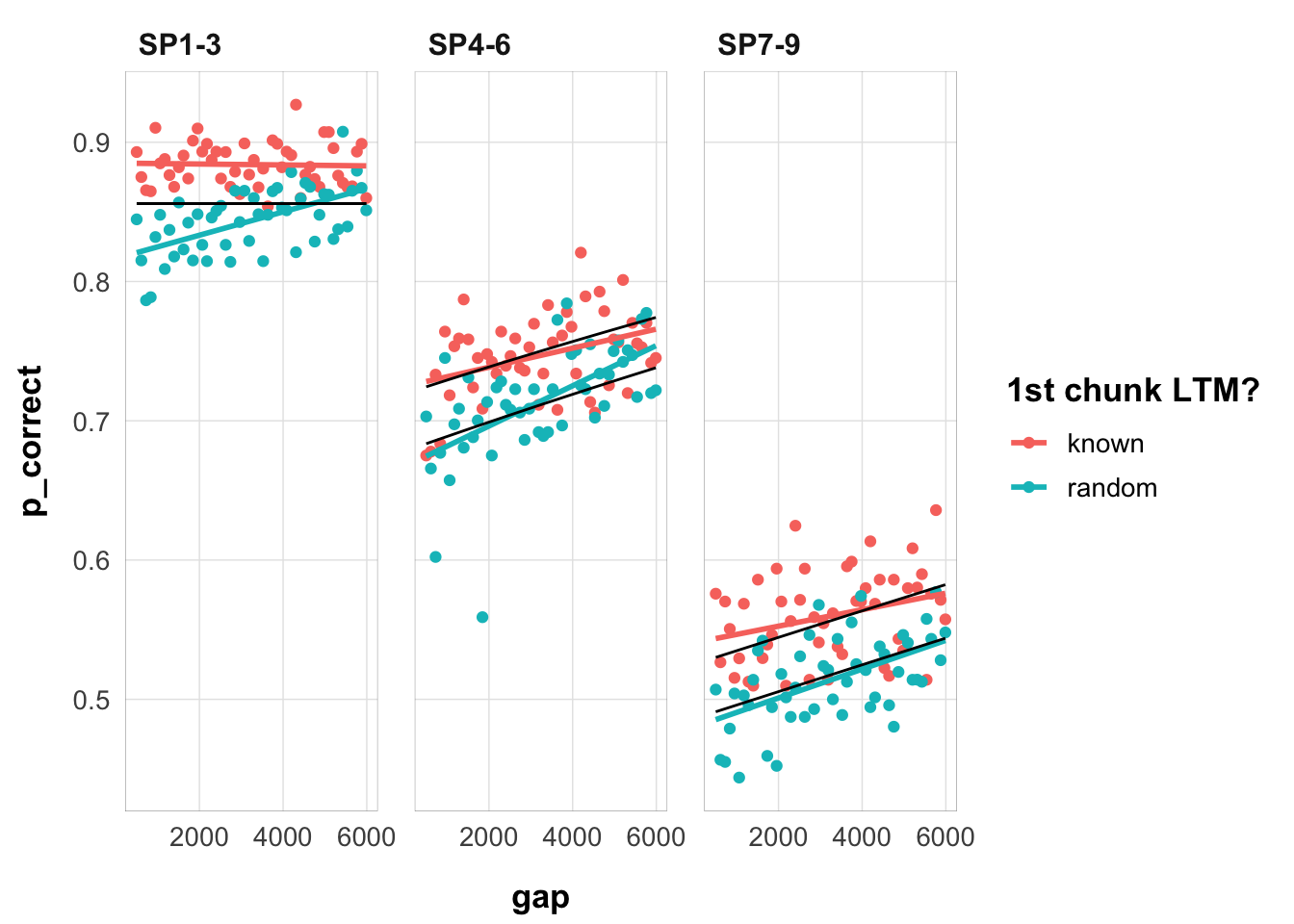
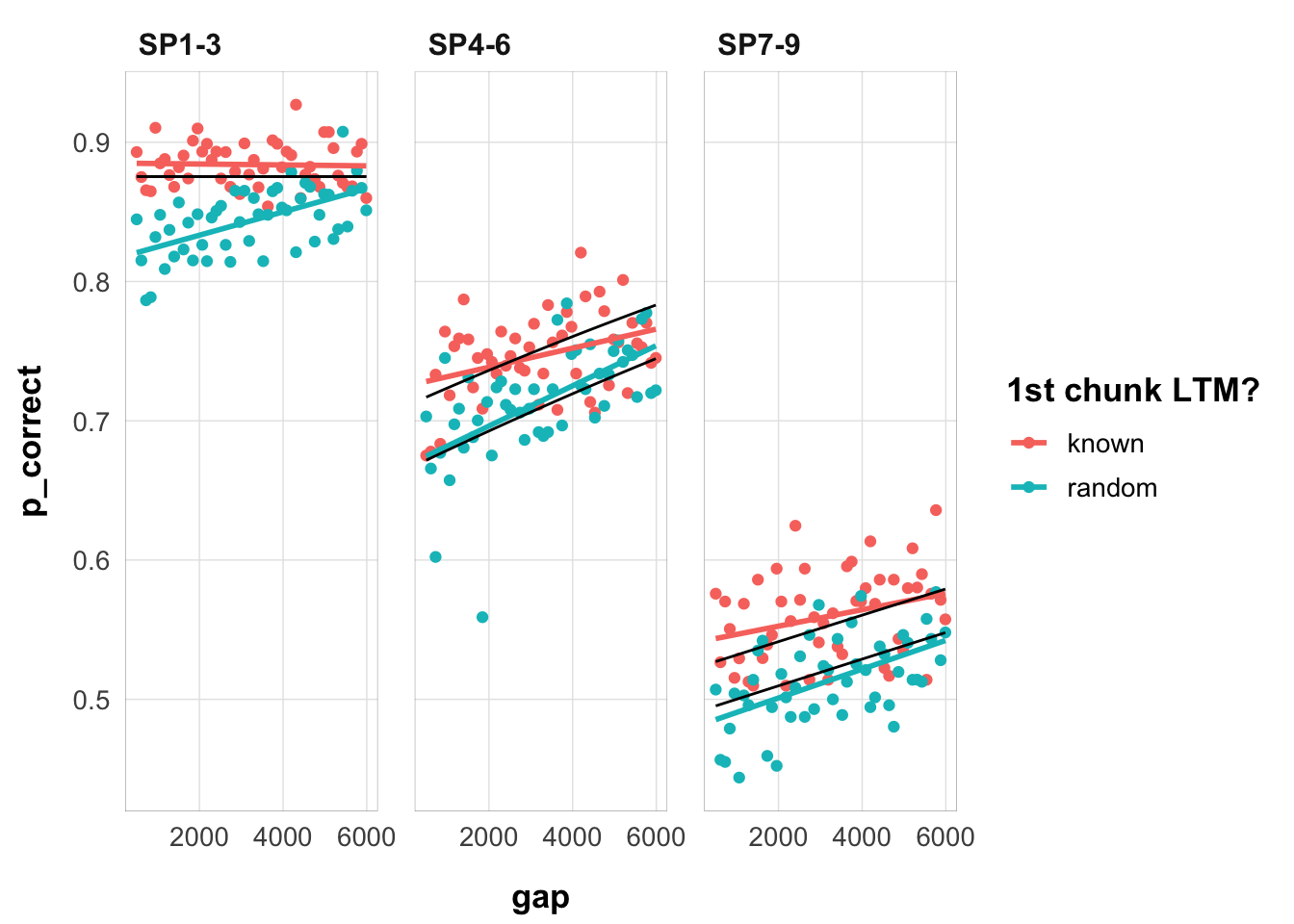
fits1_e3 |>filter(priors_scenario =="rate", exclude_sp1 ==TRUE, convergence ==0) |>arrange(deviance) |>slice(1) |>select(data, pred) |>unnest(cols =everything()) |>ggplot(aes(gap, p_correct, color = chunk, group = chunk)) +geom_point() +stat_smooth(method ="lm", se =FALSE) +geom_line(aes(y = pred), color ="black") +scale_color_discrete("1st chunk LTM?") +facet_wrap(~itemtype) +theme_pub()
`geom_smooth()` using formula = 'y ~ x'
Summary
The linear recovery model cannot fit the interaction present in the data. As discussed elsewhere, this is because in order to capture the primacy effect and the global proactive benefit of free time, it needs low depletion and low recovery rates.
---title: "Experiment 3"format: html---```{r}#| label: init#| message: falselibrary(tidyverse)library(targets)tar_source()tar_load(c(exp3_data_agg))tar_load(fits1)fits1_e3 <- fits1 |>filter(exp ==3) |>mutate(deviance =pmap_dbl(list(fit, data, exclude_sp1),~overall_deviance(params =`..1`$par, data =`..2`, exclude_sp1 =`..3`) ),pred =map2(fit, data, ~predict(.x, .y, group_by =c("chunk", "gap"))) )```## Basic fitFit starting from the parameters reported in the draft for Experiment 1:```{r}est <-run_or_load(estimate_model(start =paper_params(),data = exp3_data_agg,two_step =TRUE,exclude_sp1 =TRUE,simplify =TRUE,prior =list(rate =list(mean =0.05, sd =0.01) ) ),file ="output/exp3_basic_fit.rds")est``````{r}#| label: exp3_performance#| fig-width: 8.5#| fig-height: 5exp3_data_agg$pred <-predict(est$fit[[1]], data = exp3_data_agg, group_by =c("chunk", "gap"))exp3_data_agg |>ggplot(aes(gap, p_correct, color = chunk, group = chunk)) +geom_point() +stat_smooth(method ="lm", se =FALSE) +geom_line(aes(y = pred), color ="black") +scale_color_discrete("1st chunk LTM?") +facet_wrap(~itemtype) +theme_pub()```These are the best fitting parameters when running with 100 different starting points: ```{r}fits1_e3 |>filter(exclude_sp1 ==TRUE, priors_scenario =="none") |>arrange(deviance) |>select(prop:deviance) |>head(15) |> kableExtra::kable()```The fits require very slow rate again. Here's the plot of the best fitting parameters:```{r}fits1_e3 |>filter(exp ==3, exclude_sp1 ==TRUE, priors_scenario =="none") |>arrange(deviance) |>slice(1) |>select(data, pred) |>unnest(cols =everything()) |>ggplot(aes(gap, p_correct, color = chunk, group = chunk)) +geom_point() +stat_smooth(method ="lm", se =FALSE) +geom_line(aes(y = pred), color ="black") +scale_color_discrete("1st chunk LTM?") +facet_wrap(~itemtype) +theme_pub()```### Trying priors of the gain parameterLike for Experiment 1, restrict the gain to be ~ 25```{r}fits1_e3 |>filter(priors_scenario =="gain", exclude_sp1 ==TRUE, convergence ==0) |>select(prop:convergence) |>arrange(deviance) |>mutate_all(round, 3) |>print(n =10)```plot of the best fitting parameters:```{r}fits1_e3 |>filter(priors_scenario =="gain", exclude_sp1 ==TRUE, convergence ==0) |>arrange(deviance) |>slice(1) |>select(data, pred) |>unnest(cols =everything()) |>ggplot(aes(gap, p_correct, color = chunk, group = chunk)) +geom_point() +stat_smooth(method ="lm", se =FALSE) +geom_line(aes(y = pred), color ="black") +scale_color_discrete("1st chunk LTM?") +facet_wrap(~itemtype) +theme_pub()```### Trying priors of the rate parameterLike for Experiment 1, rate parameter prior ~ Normal(0.1, 0.01)```{r}fits1_e3 |>filter(priors_scenario =="rate", exclude_sp1 ==TRUE, convergence ==0) |>select(prop:convergence) |>arrange(deviance) |>mutate_all(round, 3) |>print(n =10)```plot of the best fitting parameters:```{r}fits1_e3 |>filter(priors_scenario =="rate", exclude_sp1 ==TRUE, convergence ==0) |>arrange(deviance) |>slice(1) |>select(data, pred) |>unnest(cols =everything()) |>ggplot(aes(gap, p_correct, color = chunk, group = chunk)) +geom_point() +stat_smooth(method ="lm", se =FALSE) +geom_line(aes(y = pred), color ="black") +scale_color_discrete("1st chunk LTM?") +facet_wrap(~itemtype) +theme_pub()```## SummaryThe linear recovery model cannot fit the interaction present in the data. As discussed elsewhere, this is because in order to capture the primacy effect and the global proactive benefit of free time, it needs low depletion and low recovery rates.